決定係数が高ければOKは危ない!決定係数を正しく理解しよう
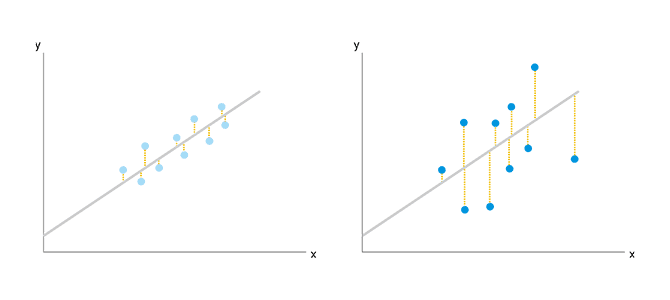
重回帰分析の結果を読み取る指標のひとつ「決定係数」。1に近いほど分析の精度が高いことを表します。しかし、決定係数だけに気を取られていると分析結果を読み違えてしまうことも。決定係数を正しく理解しましょう。
回帰分析の分析結果で一番気になるものの一つが決定係数ではないでしょうか。 決定係数とは、回帰分析によって求められた目的変数の予測値が、実際の目的変数の値とどのくらい一致しているかを表している指標です。 回帰分析には、y=ax+bという式で表すことができる単回帰分析と、説明変数が複数ある重回帰分析があります。まずは単回帰分析から見ていき、決定係数とは何か? を考えてみましょう。

関連資料の無料ダウンロード
マーケターに力を与える、Excelでできる重回帰分析ガイド
~マーケティング施策と事業成果の相関が理解できる~
単回帰分析における決定係数
単回帰分析ではy=ax+bの形で目的変数(y)の値を予測しますが、あくまで「予測値」のため実際の目的変数の値とは完全に一致しません。 そのため、何を説明変数(x)とするかによって、「予測がほぼ当たっている」場合と「あまり当たっていない」場合があります。

上図の左が「ほぼ当たっている」状態で、右が「あまり当たっていない」状態であることが分かると思います。 こういった2つのケースを比較するために「予測がどのくらい当たっているか」を客観的に示す指標が決定係数です。 決定係数は0から1の範囲内の値を取り、1に近ければ近いほど予測が当たっている状態で、0に近ければ近いほど予測があまり当たっていない状態を表します。この数字は、厳密には「回帰分析をした結果が目的変数のばらつき(分散)をどれくらい説明しているか」によって定義されています。
重回帰分析における決定係数
続いて、重回帰分析です。説明変数が2つの場合を図示してみましょう。

2次元だった単回帰分析とは異なり、3次元の空間に点が宙に浮いている状態となりますが、基本的な考え方は変わりません。 この場合でも「(この図の場合は)xとzから求められるyの予測値が、実際のyの値とどれだけ一致しているか」を表すのが決定係数です。 先ほどの2次元の回帰分析の場合と同じように、誤差が小さくなる(予測が当たっている)ほど決定係数は大きくなります。
「決定係数」と「自由度調整済み決定係数」
ここまで回帰分析および重回帰分析における決定係数について説明してきました。 一般的な統計ソフトを用いて回帰分析を行う場合には、決定係数と並んで「自由度調整済み決定係数」が表示されることも多いかと思いますので、この2つの違いについても簡単に説明します(ここから先の話はやや専門的になるので、難しいと感じたら結論まで読み飛ばして頂いても大丈夫です)。 「日本の国民全体からランダムに1000人選んでアンケートを行う」ことを考えてみましょう。
このアンケートの結果にもとづいて回帰分析を行い、そこで得られた回帰係数をもとに決定係数を出したとします。しかしながら、ここで求められた回帰係数はあくまで「たまたま選ばれた1000人」に対して最も予測が当たるように求められたものです。(現実的には不可能ですが)日本の国民全員を対象に「たまたま選ばれた1000人」に最適化された結果を適用すると、一般に予測が悪くなるはずです。 決定係数は「たまたま選ばれた1000人」への予測の当てはまりだけを見ている指標です。そのためこれを「日本の国民全体を対象」とした決定係数と考えようとすると、予測の当てはまりの良さを課題に見積もっていることになり不適切です。
こうした問題に対処し、あくまで「日本の国民全体を対象」とした予測値の当てはまりを評価できるよう決定係数の値を修正したものが「自由度調整済み決定係数」です。値の修正にはサンプル数と説明変数の個数から求められる「自由度」という数字を使っているため、この名前がつけられています。
我々が明らかにしたいのは「たまたま選ばれた1000人」の性質よりも、「日本の国民全体」(あるいはマーケティングの文脈なら「ターゲットとする顧客セグメント全体」など)の性質であることがほとんどでしょう。その文脈に照らし合わせると、自由度調整済み決定係数の方が決定係数より好ましい性質を持っていると言えます。そのため決定係数と自由度調整済み決定係数の両方が出力されている場合は、自由度調整済み決定係数の方を参照しましょう。
決定係数は絶対の指標ではない
ここまで決定係数について説明してきましたが、「(自由度調整済み)決定係数さえ高ければなんでもよい」という考え方はもちろん不適切です。 分析を行うからにはその目的があり、検証したい仮説があるはずです。こうした目的や仮説とは一切関係ない変数を、決定係数が上がるからという理由だけで無秩序に分析に加えてしまうと、そのモデルは解釈が難しくなり当初の目的を果たせないでしょう。
また決定係数はあくまで「予測の当てはまりの良さ」を表す指標です。分析の目的が「ある変数の値を予測したい」の場合には適切な指標ですが、「雨が降った日数がコンビニの月間の売上に影響があるかどうか知りたい」のように、ある変数の影響の有無が主眼であり予測は重視しない場合には、決定係数に注目することはあまり意味がないと言えます。この場合には「雨が降った日数」という説明変数の回帰係数や、その係数に対する検定の結果(有意かどうか)にまず注目すべきでしょう。
決定係数は分かりやすく便利な指標であるため、分析の際にはどうしてもここだけに目が行きがちです。しかしながら、本当に価値のある分析をするためには、数字の意味をしっかり理解した上で、分析の目的と照らし合わせて正しく使うことが求められます。

事例資料の無料ダウンロード
統計を用いた広告効果分析:
業態別にMMM活用事例集
マーケティングと重回帰分析これまでのまとめ
マーケティングに役立てたい! 重回帰分析の基本をまとめました。
図で学ぶとわかりやすいんです!|マーケティングと重回帰分析-その1
マーケティング分野に重回帰分析がピッタリな理由や、重回帰分析を図を使ってわかりやすく紹介しています。
7つの統計用語を知りましょう|マーケティングと重回帰分析-その2
統計にはたくさんの用語が登場しますね。その中でも、これだけ押さえればOKの統計用語7つを集めました。
読めば納得。重回帰分析で失敗しがちな事例10|マーケティングと重回帰分析−その3
こんなとき、どうする?の解決方法も合わせて、重回帰分析で失敗しがちな事例が10パターン。
広告やマーケティング活動による事業成果の予測分析
時系列データと回帰分析を用いて、未来の予算をどこにいくら投資するか、それによりどのぐらいの成果を生み出せるかなど、データを根拠にした意思決定が可能になります。